GraphQL Fragments
When we explored directives, I kept adding an "(or fragment)" whenever I mentioned the use of that directive. It is now time to explore my favorite feature of the GraphQL language. Fragments!
1. Why fragments?
To build anything big or complicated, the one and only truly helpful strategy is to split what needs to be built into smaller parts and then focus on one part at a time. Ideally, the smaller parts should be designed in a way that does not couple them with each other. They should be testable on their own and they should also be reusable. A big system should be the result of putting these parts together and having them communicate with each other to form features.
For example, in the User Interface (UI) domain, the React.js library popularized the idea of using small components to build a full UI. React.js certainly was not the first library to use the concept of components, but it did make most UI developers aware of components benefits.
In GraphQL, fragments are the composition units of the language. They provide a way to split big GraphQL operations into smaller parts. A fragment in GraphQL is simply a reusable piece of any GraphQL operation.
I like to compare GraphQL fragments to UI components. Fragments, if you will, are the components of a GraphQL operation.
Splitting a big GraphQL document into smaller parts is the main advantage of GraphQL fragments. However, fragments can also be used to avoid duplicating a group of fields in a GraphQL operation. We will explore both benefits but let’s first understand the syntax for defining and using fragments.
2. Defining and using fragments
To define a GraphQL fragment, you can use the “fragment” top-level keyword in any GraphQL document. You give the fragment a name and specify on what type that fragment can be used. Then, you write a partial query to represent the fragment.
For example, let’s take the simple GitHub organization information query example:
query OrgInfo {
organization(login: "facebook") {
name
description
websiteUrl
}
}
To make this query use a fragment for the fields of the organization, you first need to define the fragment:
fragment orgFields on Organization {
name
description
websiteUrl
}
This defines an orgFields fragment that can be used within a selection set that expands an organization object. The “on Organization” part of the definition in listing 10.1 is called the "Type Condition" of the fragment. Since a fragment is essentially a selection set, you can only define fragments on object types. You cannot define a fragment on a scalar value.
To use the fragment, you "spread" its name where the fields were originally used in the query:
query OrgInfoWithFragment {
organization(login: "facebook") {
...orgFields
}
}
The three dots before orgFields in listing 10.2 are what you can use to spread orgFields. The concept of spreading a fragment is similar to the concept of spreading an object in JavaScript. The same three-dots operator can be used in JavaScript to spread an object inside another object, effectively cloning that object.
The three-dotted fragment name (…orgFields) is called a "Fragment Spread". You can use a fragment spread anywhere you use a regular field in any GraphQL operation.
A fragment spread can only be used when the type condition of that fragment matches the type of the object in which you want to use the fragment. There are no generic fragments in GraphQL. Also, when a fragment is defined in a GraphQL document, that fragment must be used somewhere. You cannot send a GraphQL server a document that just defines fragments and does not use them.
3. Fragments and DRY
Fragments can be used to reduce any duplicated text in a GraphQL document. Consider this example query from the GitHub API:
query MyRepos {
viewer {
ownedRepos: repositories(affiliations: OWNER, first: 10) {
nodes {
nameWithOwner
description
forkCount
}
}
orgsRepos: repositories(affiliations: ORGANIZATION_MEMBER, first: 10) {
nodes {
nameWithOwner
description
forkCount
}
}
}
}
This query uses a simple alias with field arguments to have two lists of identical structure, one list for the repositories owned by the current authenticated user and the other list of all the repositories under organizations of which the current authenticated user is a member.
This is a simple query but there is room for improvement. The fields under a repository connection are repeated. We can use a fragment to define these fields just once and then use that fragment in the two places where the nodes field is repeated. The nodes field is defined on the special RepositoryConnection in GitHub (it is the connection between a user and a list of repositories).
Here is the same GraphQL operation modified to use a fragment to remove the duplicated parts:
query MyRepos {
viewer {
ownedRepos: repositories(affiliations: OWNER, first: 10) {
...repoInfo
}
orgsRepos: repositories(affiliations: ORGANIZATION_MEMBER, first: 10) {
...repoInfo
}
}
}
fragment repoInfo on RepositoryConnection {
nodes {
nameWithOwner
description
forkCount
}
}
Pretty neat, right? But as I mentioned, the DRY benefit of fragments is the less important one. The big advantage of fragments is the fact that they can be matched to other units of composition (like UI components). Let’s talk about that!
4. Fragments and UI components
The word component can mean different things to different people. In the UI domain, a component can be an abstract input text box or Twitter’s full 280-character tweet form with its buttons and counter display. You can pick any part of an application and call that a component. They can be small or big. They can be functional on their own or they can just be parts that have to be put together to make something functional.
Bigger components can be composed from smaller ones. For example, the Twitter’s TweetForm component can be composed from a TextArea component with a TweetButton component and a few other others to attach an image, add a location, and count the number of characters typed in the text area.
All HTML elements can be considered simple components. They have properties and behaviors, but they are limited in the fact that they cannot represent dynamic data. The story of UI components gets interesting when we make a component represent data. We can do that with modern libraries and frameworks like React.js, Angular.js, and Polymer.js. These data components can then be reused for any data that matches the shape they have been designed to work with. The data components do not really care about what that data is. They are only concerned about the shape of that data.
The idea of rich components is actually coming natively to the browser with what is commonly labeled as Web Components. Many browsers already support most of the features needed to define and use Web Components. The Polymer.js project is designed to first provide polyfills to support using Web Components in any browser and then enhance their features.
Let’s assume we are building an app like Twitter by using rich data components, and let’s take one example page from that app and analyze it in terms of components and their data requirements. I picked the user’s profile page for this example.
The user’s profile page is a simple page that displays public information about a user, some stats, and the list of their tweets. For example, if you navigate to twitter.com/ManningBooks on Twitter, you will see something like this:
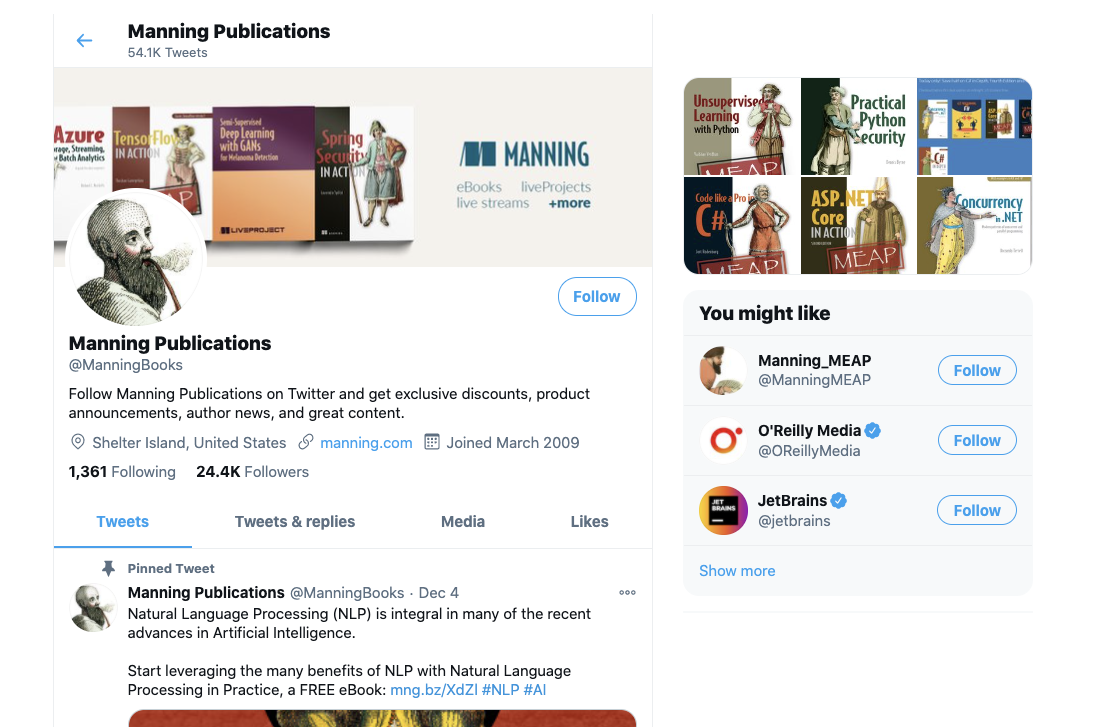
I can see at least 15 components on this page:
-
The
Headercomponent, which could include the following list of components:ProfileImage,BackgroundImage,TweetCount,FollowingCount,FollowersCount,LikesCount, andListsCount. -
The
Sidebarcomponent, which could include the following list of components:UserInfo,FollowersYouKnow,UserMedia, andMediaItem. -
The
TweetListcomponent, which is simply list ofTweetcomponents.
This is just my choice of components. This page can be built with a lot more components and it can also be built with just two components. No matter how small or big the components that you design are, they will share a simple fact: they all depend on some shape of data.
For example, the Header component in this UI needs a data object to represent a profile. The shape of that data object might look like this:
const profileData = {
profileImageUrl: ...,
backgroundImageUrl: ...,
tweetsCount: ...,
followingCount: ...,
followersCount: ...,
likesCount: ...,
listsCount: ...,
};
The TweetList component needs a data object that might look like this:
const tweetList = [
{ id: ...,
userName: ..,
userHandle: ...,
date: ...,
body: ...,
repliesCount: ...,
tweetsCount: ...,
likes: ...,
},
{ id: ...,
userName: ..,
userHandle: ...,
date: ...,
body: ...,
repliesCount: ...,
tweetsCount: ...,
likesCount: ...,
},
...,
];
These components can be used to render information about any profile and any list of tweets. The same TweetList component can be used on Twitter’s main page, a user’s list page, or the search page.
As long as we feed these components the exact shape of data they need, they will just work. This is where GraphQL comes into the picture because we can use it to describe the shape of data needed by an application.
To simplify the Twitter example, I will consider that we are going to build the profile page with just these main four components: Header, Sidebar, TweetList, and Tweet.
A GraphQL query can be used to describe an application data requirement. The data required by an application is the sum of the data required by that application’s individual components and GraphQL fragments offer a way to split a big query into smaller ones. This makes a GraphQL fragment the perfect match for a component! We can simply use a GraphQL fragment to represent the data requirements for a single component and then put these fragments together to compose the data requirements for the whole application.
Let’s come up with the data required by the Twitter’s profile page example using a single GraphQL query for each component we identified.
The data required by the Header component can be declared using this GraphQL fragment:
fragment headerData on User {
profileImageUrl
backgroundImageUrl
tweetsCount
followingCount
followersCount
likesCount
listsCount
}
The data required by the Sidebar component can be declared using:
fragment sidebarData on User {
userName
handle
bio
location
url
createdAt
followersYouKnow {
profileImageUrl
}
media: {
mediaUrl
}
}
Note that the followersYouKnow part and the media part can also come from the sub-components we identified earlier in the Sidebar component.
The data required by a single Tweet component can be declared using:
fragment tweetData on Tweet {
user {
userName
handle
}
createdAt
body
repliesCount
retweetsCount
likesCount
}
Finally, the data required by the TweetList component is an array of the exact data required by a single Tweet component. So, we can use the tweetData fragment here:
fragment tweetListData on TweetList {
tweets: {
...tweetData
}
}
To come up with the data required by the whole page, all we need to do is put these fragments together and form one GraphQL query using fragment spreads:
query ProfilePageData {
user(handle: "ManningBooks") {
...headerData
...sidebarData
...tweetListData
}
}
Now we can send this single profilePageData query to the GraphQL server and get back all the data needed for all the components on the profile page.
When the data comes back, we can identify which component requested which parts of the response and make those parts available to only the components that requested them. This helps isolate a component from any data that it does not need.
But this is not the coolest thing about this approach. By making every component responsible for declaring the data it needed, these components will have the power to change their data requirements when necessary without having to depend on any of their parent components in the tree.
For example, let’s assume Twitter decided to show the number of views each tweet has received next to the likesCount. All we need to do to satisfy this new data requirement is to modify the tweetData fragment:
fragment tweetData on Tweet {
user {
userName
handle
}
createdAt
body
repliesCount
retweetsCount
likesCount
viewsCount
}
None of the other components in the application need to worry about this change or even be aware of it. For example, the direct parent of a Tweet component, the TweetList component, does not need to be modified to make this change happen. That component always constructs its own data requirements by using the Tweet component’s data requirement no matter what that Tweet component asked for. This is simply great. It makes maintaining and extending this app a much easier task.
Fragments are to queries what UI components are to a full application. By matching every UI component in the application to a GraphQL fragment, we give these components the power of independence. Each component can declare its own data requirement using a GraphQL fragment and we can compose the data required by the full application by just putting these GraphQL fragments together.
5. Inline Fragments for Interfaces and Unions
In a previous chapter, we saw an example of an inline fragment when we talked about The Node Interface. Inline fragments are, in a way, similar to anonymous functions that you can use without a name. They are just fragments without names and you can spread them inline where you define them.
Here is an inline fragment use case from the GitHub API:
query InlineFragmentExample {
repository(owner: "facebook", name: "graphql") {
ref(qualifiedName: "master") {
target {
... on Commit {
message
}
}
}
}
}
Inline fragments can be used as a type condition when querying against an interface or a union. The bolded part in the query in listing 10.13 is an inline fragment on the Commit type within the target object interface, so to understand the value of inline fragments you will need to first understand the concepts of unions and interfaces in GraphQL.
Interfaces and unions are abstract types in GraphQL. An interface defines a list of fields and a union defines a list of possible object types. Object types in a GraphQL schema can implement an interface, which forms a guarantee that the implementing object type will have the list of fields defined by the implemented interface. Object types defined as unions guarantee that what they return will be one of the possible types of that union.
In the previous example query, the target field is an interface that represents a Git object. Since a Git object can be a commit, tag, blob, or tree, all these object types in the GitHub API implement the GitObject interface and, because of that, they all get a guarantee that they implement all the fields a GitObject implements (like repository, since a Git object belongs to a single repository).
Within a repository, the GitHub API has the option to read information about a Git reference using the ref field. Every Git reference points to an object, which the GitHub API named target. Now, since that target can be one of four different object types that implement the GitObject interface, within a target field, you can expand the selection set with the interface fields, but you can also conditionally expand its selection set based on the type of that object. If the object that this ref points to happens to be a Commit, what information out of that commit are you interested in? What if that object is a Tag?
This is where inline fragments are useful because they basically represent a type condition. The inline fragment in the previous query essentially means this exact condition: If the object pointed to by the reference is a commit, then return the message of that commit. Otherwise, the target will return nothing. You can use another inline fragment to add more cases for the condition.
The union concept is probably a bit easier to understand. It is basically an OR logic. A type can be this or that. In fact, some union types are named as xOrY. In the GitHub API, you can see an example of that under a repository field, where you can ask for issueOrPullRequest. Within this union type, the only field you can ask for is the special __typename, which can be used to answer the question "Is this an issue or a pull request?"
Here is an example from the "facebook/graphql" repository:
query RepoUnionExample {
repository(owner: "facebook", name: "graphql") {
issueOrPullRequest(number: 3) {
__typename
}
}
}
The issueOrPullRequest with number 3 on this repository happens to be an issue. If you try the query with number 5 instead of 3, you should see a pull request, so an inline fragment is useful here to conditionally pick fields within an issueOrPullRequest based on the type. For example, maybe we are interested in the merge information of a pull request and the closing information of an issue. Here is a query to pick these different fields based on the type of the issueOrPullRequest whose number is 5:
query RepoUnionExampleFull {
repository(owner: "facebook", name: "graphql") {
issueOrPullRequest(number: 5) {
... on PullRequest {
merged
mergedAt
}
... on Issue {
closed
closedAt
}
}
}
}
Since #5 (in this repository) is a pull request, the merged and mergedAt fields will be used for this query.
Another common use of union types is to implement a search field to search among multiple types. For example, a GitHub user search might return a user object or an organization object. Here is a query to search GitHub users for the term "graphql":
query TestSearch {
search(first: 100, query: "graphql", type: USER) {
nodes {
... on User {
name
bio
}
... on Organization {
login
description
}
}
}
}
You should see users who have the term "graphql" somewhere in their profile, and organizations who have that term in their name or description. When the matching returned item is a User object, the fields name and bio will be returned and when the item is an Organization object, the fields login and description will be returned.