Customizing and Organizing GraphQL Operations
In any non-trivial application, you will have to do many things beyond asking the server a direct and simple single-value question. Data fetching is usually coupled with variables and meta questions about the structure of the response. You often need to modify the data returned by the server to make it suitable for your application needs. Sometimes, you need to remove parts of the data or go back to the server and ask for other parts that are needed based on conditions in your application. You also need a way to organize big requests and categorize them to know which part of your application is responsible for each part in your requests. Luckily, the GraphQL language offers many built-in features that will allow you to do all of the above and much more. These customizing and organizing features are what this chapter is all about.
1. Customizing Fields with Arguments
The fields in a GraphQL operation are similar to functions. They map input to output. A function input is received as a list of argument values. Just like functions, we can pass any GraphQL field a list of argument values. A GraphQL schema on the backend will have access to these values and can use them to customize the response they return for that field.
Let’s look at some use cases for these field arguments and examples of these cases as used by the GitHub GraphQL API (developer.github.com).
1.1. Identifying a single record to return
Every API request that asks for a single record from a collection needs to specify an identifier for that record. This identifier is usually associated with a unique identifier for that record in the server’s database, but it can also be anything else that can uniquely identify the record.
For example, if you are asking an API for information on a single user, you would usually send along with your request the ID for the user you are interested in. You can also send their email address, username, or their Facebook-id connection if, for example, you are logging them in through a Facebook button.
Here is an example query that could be asking for information about the user whose email address is "[email protected]":
query UserInfo {
user(email: "[email protected]") {
firstName
lastName
userName
}
}
The email part inside the user field is called a field argument.
Note that for an API field that represents a single record, the argument value that you pass to identify that record has to be a unique value on that field record in the database. For example, you cannot pass the full name of the person to identify their user record because the database might have many people who have the same name.
However, you can pass multiple arguments to identify the user. For example, you can pass a full name and an address to uniquely identify a single person record.
Examples of single record fields are popular. Some GraphQL APIs even have a single record field for every object in the system. This is commonly known in the GraphQL world as "The Node Interface", which is a concept that was popularized by the Relay framework (which also originated at Facebook). With The Node Interface, you can look up any node in the data graph by its global system-wide unique ID. Then, based on what that node is, you can use an inline fragment to specify what properties on that node you are interested to see in the response.
query NodeInfo {
node(id: "A-GLOBALLY-UNIQUE-ID-HERE") {
...on USER {
firstName
lastName
userName
email
}
}
}
We’ll talk more about GraphQL Fragments in the next chapter.
In the GitHub API, some examples of single record fields are user, repository, project, organization, and many more. Here is an example to read information about the Facebook organization, which is the organization that hosts the official GraphQL specification repository.
query OrgInfo {
organization(login: "facebook") {
name
description
websiteUrl
}
}
1.2. Limiting the number of records returned by a list field
When you ask any API for a list of records from a collection, a good API will always ask you to provide a limit. How many records are you interested in?
It is usually a bad idea to leave a general API capability that enable listing records in a collection without a limit. You do not want to have a way for a client to fetch more than a few hundred records at a time because that would put your API server under the risk of resource exhaustion and will not scale very well. This is exactly why the GitHub API requires the use of an argument like first (or last) when you ask it for a list of records. Go ahead and try to ask for all the repositories under the Facebook organization. You can use the repositories field within the organization field in the OrgInfo query of listing 9.3. You should notice how GitHub will ask for a first or last value:
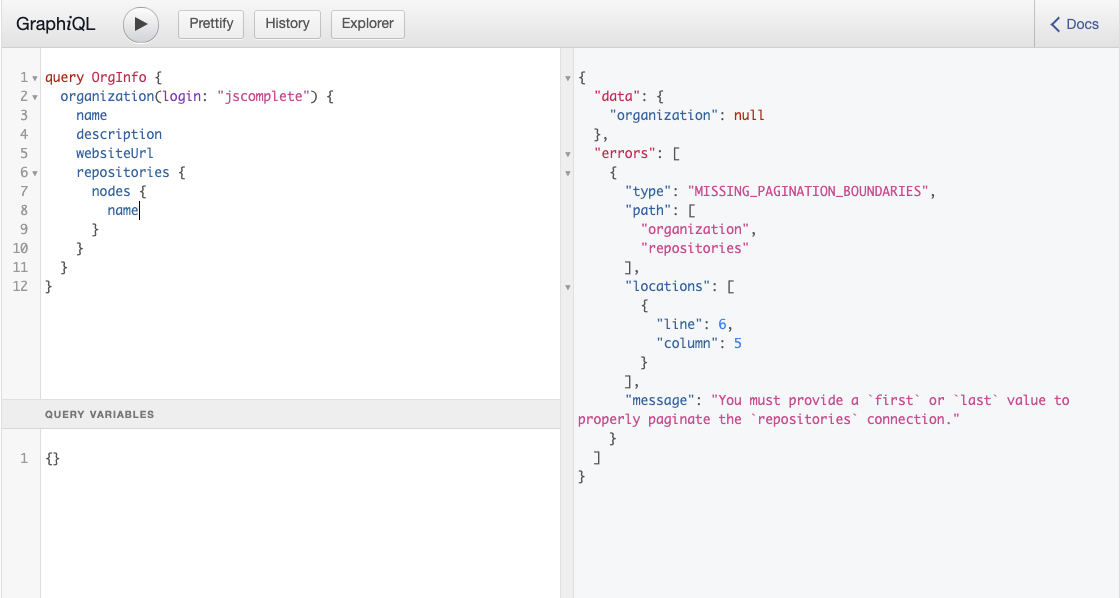
Since any list of records in a database will have a certain order, you can limit your request results using either end of that order. If you are interested in 10 records, you can either get the first 10 records or the last 10 records using these arguments.
Here is the query that you can use to retrieve the first 10 repositories under the Facebook organization:
query First10Repos {
organization(login: "facebook") {
name
description
websiteUrl
repositories(first: 10) {
nodes {
name
}
}
}
}
By default, the GitHub API will order the repositories by their date of creation in an ascending order. You can customize that ordering logic with another field argument!
1.3. Ordering records returned by a list field
In the previous example, the GitHub API ordered the list of repositories under the Facebook organization by the CREATED_AT repository order field. The API supports many other order fields, including UPDATED_AT, PUSHED_AT, NAME, and STARGAZERS.
Here is a query to retrieve the first 10 repositories when they are ordered alphabetically by name:
query orgReposByName {
organization(login: "facebook") {
repositories(first:10, orderBy:{field: NAME, direction: ASC}) {
nodes {
name
}
}
}
}
Can you use the GitHub field arguments you learned about to find out the top-10 most popular repositories under the Facebook organization? Base a repository’s popularity on the number of stars it has.
Here is one query you can use for that:
query OrgPopularRepos {
organization(login: "facebook") {
repositories(first:10, orderBy:{field: STARGAZERS, direction: DESC}) {
nodes {
name
}
}
}
}
1.4. Paginating through a list of records
When you need to retrieve a page of records, in addition to specifying a limit, you need to specify an offset.
In the GitHub API, you can use the field arguments after or before to offset the results returned by the arguments first or last.
To use these arguments, you need to work with node identifiers, which are different than database record identifiers. The pagination interface that the GitHub API is using is called The Connection Interface (which originated from the Relay framework as well). In that interface, every record is identified by a node field (similar to the Node Interface) using a cursor field. The cursor is basically the ID field for each node and it is the field that we can use with the before and after arguments.
To have a way to work with every node’s cursor next to that node’s data, the Connection Interface adds a new parent to the node concept called "edge". The edges field can represent a list of paginated records and every object in that list holds a unique cursor value.
Here is the stargazers query in the previous example modified to include cursor values through the edges field:
query OrgRepoConnectionExample {
organization(login: "facebook") {
repositories(first:10, orderBy:{field: STARGAZERS, direction: DESC}) {
edges {
cursor
node {
name
}
}
}
}
}
Note how within an edges field we are now asking about a single node field because the list is no longer a list of nodes but rather a list of edges where each edge is a node + cursor.
Now that you can see the string values of these cursors, you can use these values as the after or before arguments to fetch extra pages of data. For example, to fetch the second page of the most popular repositories under the Facebook organization, you need to identify the cursor of the last popular repository you see in the first page (which was "fresco" when I tested these queries) and use that cursor value as the after value:
query OrgPopularReposPage2 {
organization(login: "facebook") {
repositories(
first: 10,
after: "Y3Vyc29yOnYyOpLNOE7OAeErrQ==",
orderBy: {field: STARGAZERS, direction: DESC}
) {
edges {
cursor
node {
name
}
}
}
}
}
The introduction of the edges field also allows the addition of some meta-data about the list. For example, on the same level where we are asking for a list of edges, we can also ask about how many total records this relation has and whether there are still more records to fetch after the current page. Here is the previous query modified to show some meta-data about the relation:
query OrgReposMetaInfoExample {
organization(login: "facebook") {
repositories(
first: 10,
after: "Y3Vyc29yOnYyOpLNOE7OAeErrQ==",
orderBy: {field: STARGAZERS, direction: DESC}
) {
totalCount
pageInfo {
hasNextPage
}
edges {
cursor
node {
name
}
}
}
}
}
Since the Facebook organization has a lot more than 20 repositories (2 pages in this example), that hasNextPage field will be true to indicate that. When you fetch the very last page, the hasNextPage will turn false indicating that there is no more data for you to fetch. This is much better than having to do an extra empty page fetch to conclude that we have reached the end of the paginated data.
1.5. Searching and filtering
A field argument in GraphQL can be used to provide filtering criteria or search terms to limit the results returned by a list. Let’s see examples for both features.
In GitHub, a repository can have a list of projects to manage any work related to that repository. For example, the Twitter Bootstrap repository on GitHub started using a project per release to manage all the issues related to a single release. Here is a query that uses a search term within the projects relation to return the Twitter Bootstrap projects that start with "v4.1":
query SearchExample {
repository(owner: "twbs", name: "bootstrap") {
projects(search: "v4.1", first: 10) {
nodes {
name
}
}
}
}
Note how the projects field also implements The Connection Interface.
Some fields allow you to filter the returned list by certain properties of that field. For example, under your GitHub viewer field, you can see a list of all your repositories. By default, that list will include all the repositories that you own or can contribute to. To list only the repositories that you own, you can use the affiliations field argument:
query FilterExample {
viewer {
repositories(first: 10, affiliations: OWNER) {
totalCount
nodes {
name
}
}
}
}
1.6. Providing input for mutations
The field arguments concept is what GraphQL mutations use to accept the mutation operation’s input. In a previous chapter, we used the following mutation example to add a star to the GraphQL repository under the Facebook organization:
mutation StarARepo {
addStar(input: {starrableId: "MDEwOlJlcG9zaXRvcnkzODM0MjIyMQ=="}) {
starrable {
stargazers {
totalCount
}
}
}
}
The input value in that mutation is also a field argument. It is a required argument. You cannot perform a GitHub mutation operation without an input object. All the GitHub API mutations use this single required input field argument that represent an object. To perform a mutation, you pass the various input values as key/value pairs on that input object.
| Not all arguments are required. A GraphQL API can control which arguments are required and which are optional. |
There are a lot more cases where a field argument can be useful. Explore the GitHub API and other publicly-available GraphQL APIs to look for more useful patterns for field arguments.
2. Renaming Fields with Aliases
The alias feature in a GraphQL operation is a very simple but powerful feature because it allows you to customize a response coming from the server through the request itself. This means by using aliases you can minimize any post-response processing on the data.
Let me explain this with an example. Let’s say you are developing the profile page in GitHub. Here is a query to retrieve partial profile information for a GitHub user:
query ProfileInfo {
user(login: "samerbuna") {
name
company
bio
}
}
You get a simple user object in the response. See figure 9.2:
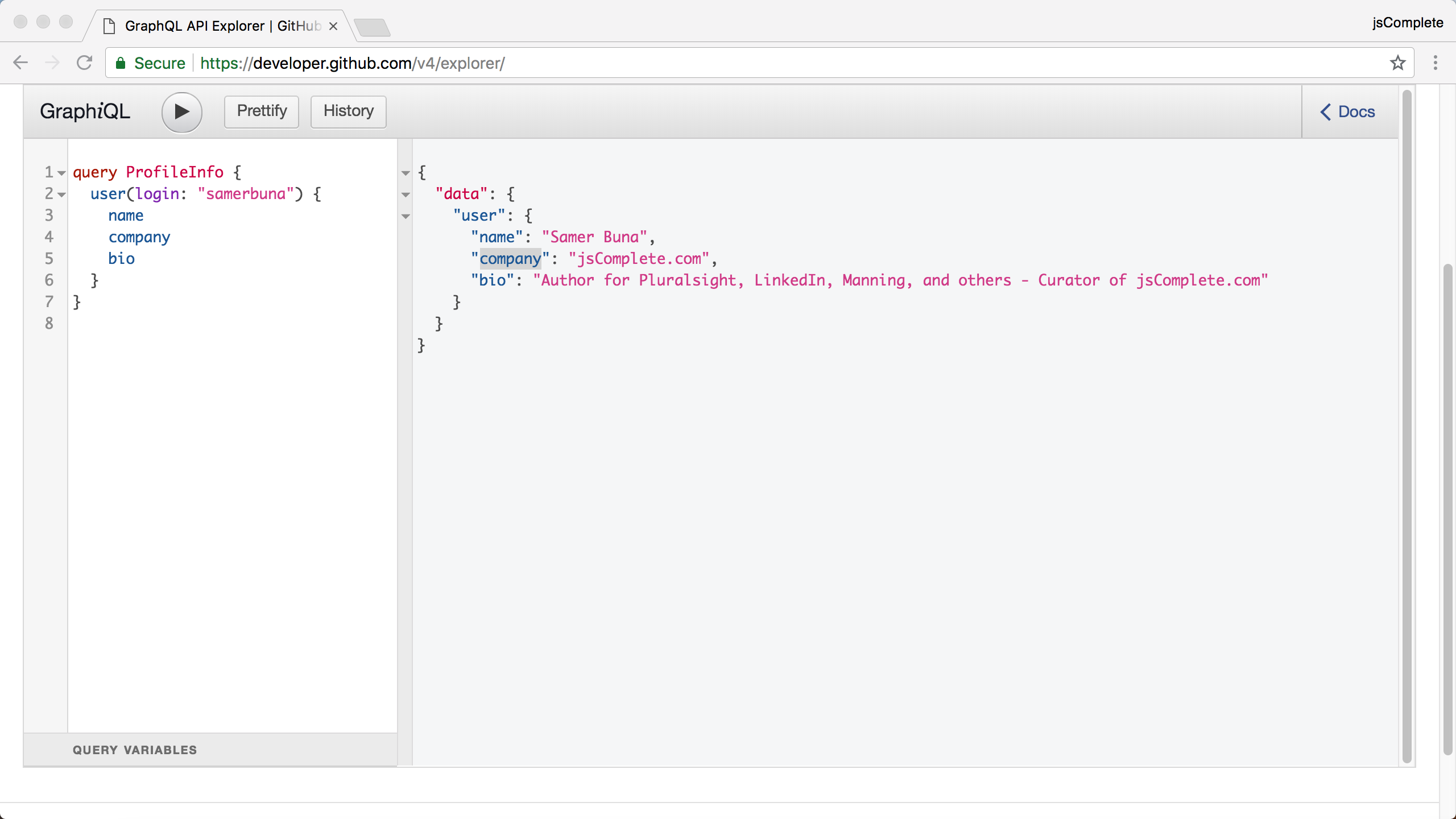
Now, an application UI can use this user object in the query’s response to substitute the values in some UI template. However, you have just discovered a mismatch between the structure of your response and the structure the application UI is using for the user object. The application UI was developed to expect a companyName field on a user instead of a company field (as found in the API response). What do you do now? Assume that changing the application UI code itself is not an option.
If you do not have the option to just use an alias, which I will show you how to do in just a bit, your other option is to process the response every time you need to use the response object. You need to transform the user object coming from the response into a new object with the right structure. This can be costly if the structure that you are working with is a deep one with multiple levels.
Luckily, in GraphQL we have this awesome alias feature that allows us to declaratively instruct the API server to return fields using different names. All you need to do is to specify an alias for that field, which you can do using the syntax:
aliasName: fieldName
Just prefix any field name with an alias and the server will return that field renamed using your alias. There is no need to process the response object.
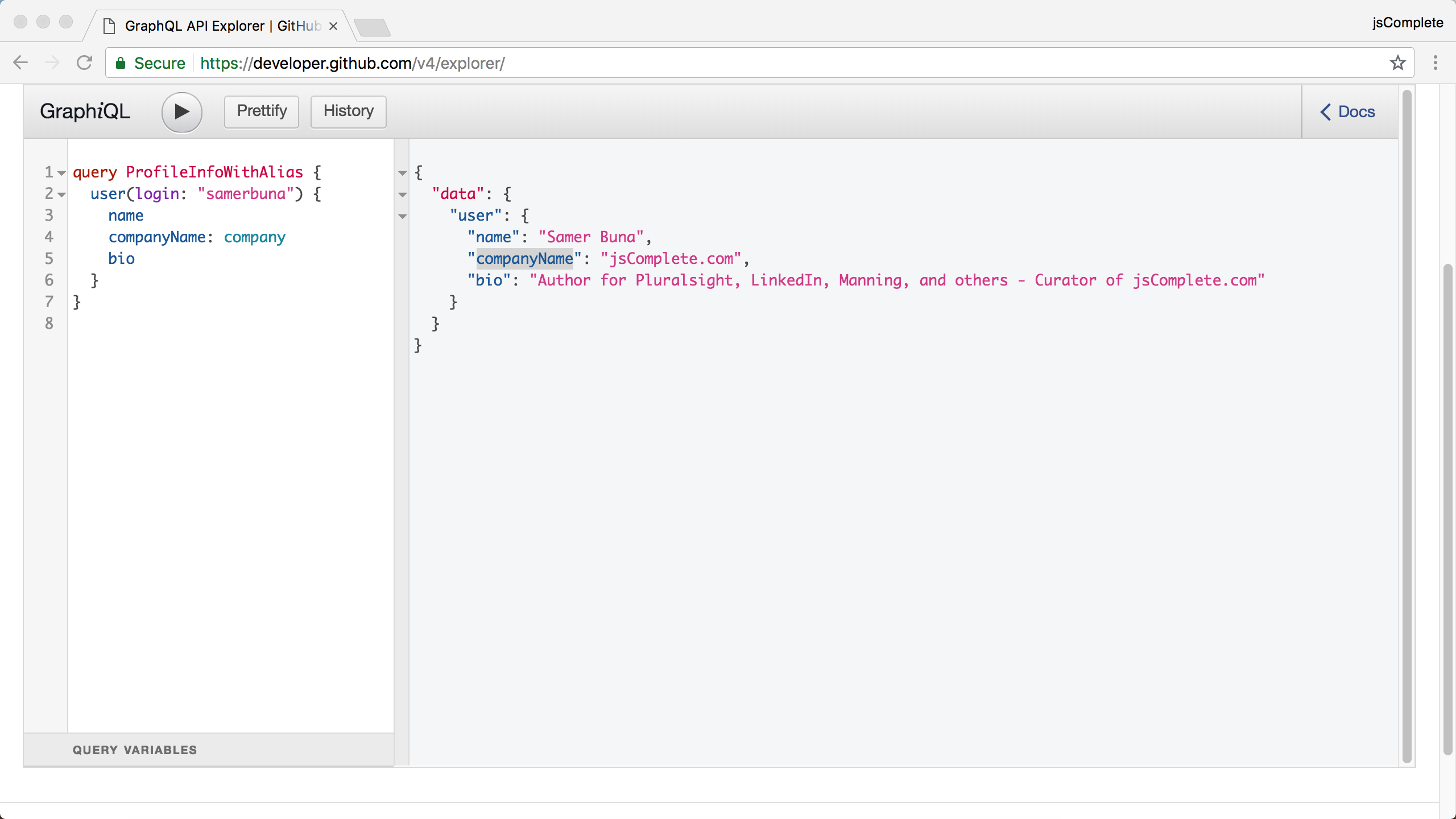
For the example in listing 9.13, all you need to do is specify a companyName alias:
query ProfileInfoWithAlias {
user(login: "samerbuna") {
name
companyName: company
bio
}
}
This will give you the exact response that is ready for you to plug into the application UI. See Figure 9.3.
3. Customizing Responses with Directives
Sometimes, the customization that you need on a server response goes beyond simple renaming of fields. Sometimes, you need to conditionally include (or exclude) branches of data in your responses. This is where the directives feature of GraphQL can be helpful.
A directive in a GraphQL request is a way to provide a GraphQL server with additional information about the execution and type validation behavior of a GraphQL document. It is essentially a more powerful version of field arguments because you can use directives to conditionally include or exclude the whole field. Also, besides fields, directives can be used with fragments and the top-level operations themselves.
A directive is any string in a GraphQL document that begins with the @ character. Every GraphQL schema has three built in directives: @include, @skip, and @deprecated. Some schemas will have more directives. You can see the list of directives supported by a schema using this introspective query:
query AllDirectives {
__schema {
directives {
name
description
locations
args {
name
description
defaultValue
}
}
}
}
This query will show the names and description for each directive and it will also include an array of all possible locations where that directive can be used. In addition, it will also include a list of all arguments supported by that directive. Each directive can optionally receive a list of arguments, and just like field arguments some argument values might be required by the API server. The response to the previous query should show that in any GraphQL schema both the @include and @skip directives have the argument “if”. The @deprecated directive has the argument “reason”.
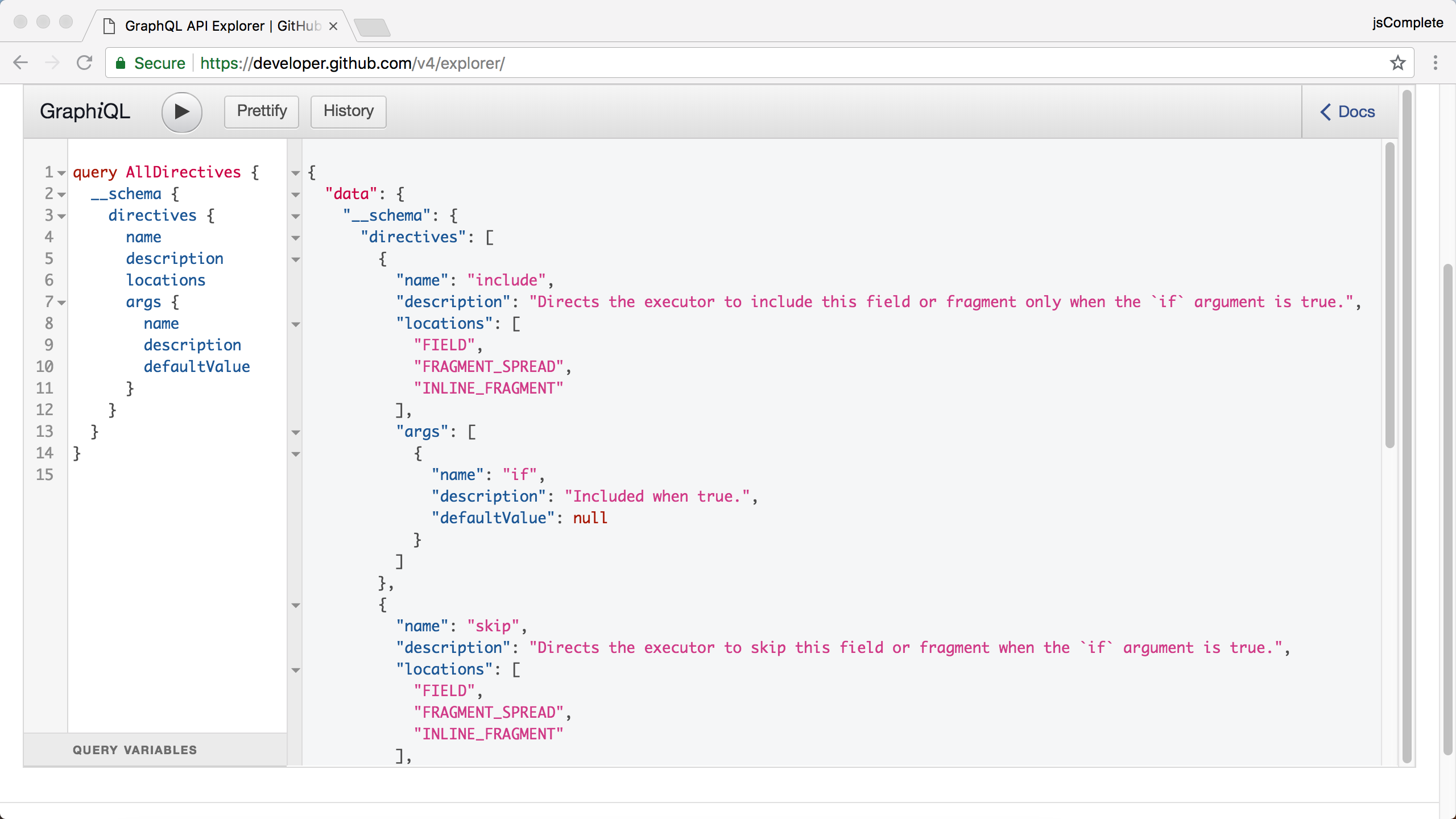
The list of locations you see in Figure 9.4 in the response of the previous query is also important. Directives can be used only in the locations they are declared to belong to. For example, the @include/@skip directives can only be used after fields or fragments. You cannot for example use them in the top-level of an operation. Similarly, the @deprecated directive can only be used after field definitions when defining a GraphQL service schema.
Since directives are usually used with arguments, they are often paired with query variables to have them sent with a dynamic value. We saw some examples of variables in a previous chapter, but let me remind you of them.
3.1. Variables and input value
A variable is simply any name in the GraphQL document that begins with a $ sign. For example, $login or $showRepositories. The name after the $ sign can be anything.
We use variables in GraphQL operations to make these operations generically reusable and avoid hard coding values and having to do string concatenation.
To use a variable in a GraphQL operation, you need to define its type first. You do that by providing arguments to any named operation. For example, let’s take the organization query example that we used to read information about the Facebook organization on GitHub. Instead of hardcoding the login value (as we did before), let’s now use a variable. The operation must have a name and then we can use that name’s arguments to define any variables. Let’s call the variable $orgLogin. It should be a required string. You can see the type of the arguments using the Docs explorer. Look up the organization field to see the types of its login argument. You can also click the organization field in the query while holding the Command key (Ctrl in Windows).
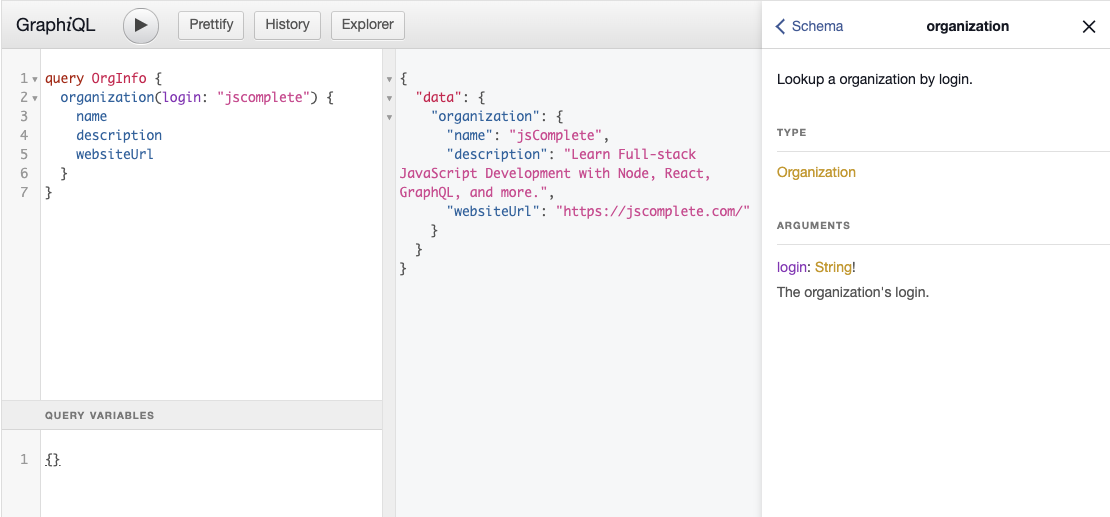
As you can see in figure 9.5, the login argument has a type of “String!”. The trailing exclamation mark on that type is GraphQL’s way of labeling the argument value as required. A value for this login argument must be specified. It cannot be null.
We can use the same syntax to define the new variable now, the type for $orgLogin should match the type of the argument where it is going to be used. Here is the same query written with this new $orgLogin variable:
query OrgInfo($orgLogin: String!) {
organization(login: $orgLogin) {
name
description
websiteUrl
}
}
Note how in the first line the query specifies that $orgLogin is also a “String!”.
You cannot execute the query in listing 9.16 as is. If you try, the GraphQL server will return an error. Since we used a variable, we must give the executor on the server the value that we wish to use as that variable. In GraphiQL, we do that using the variables editor, which is in the lower-left corner. In that editor, you write a JSON object that represents all variables you want to send to the executor along with the operation.
Since we used only one variable, the JSON object for that would be:
{
"orgLogin": "facebook"
}
Now you can execute the query with different JSON objects, making it reusable for different organizations.
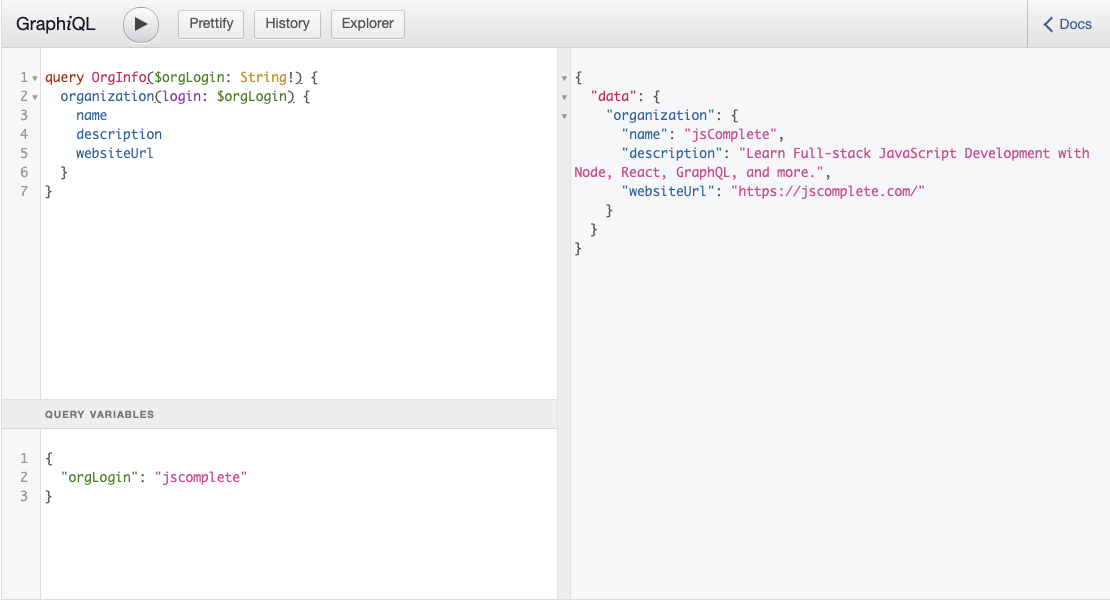
A variable like the $orgLogin can also have a default value, in which case it would not need the trailing exclamation mark. You specify the default value using an equal sign after the type of the variable. For example, the previous query can have the value "facebook" as the default value of $orgLogin using this syntax:
query OrgInfoWithDefault($orgLogin: String = "facebook") {
organization(login: $orgLogin) {
name
description
websiteUrl
}
}
You can execute this OrgInfoWithDefault query without passing a JSON object for variables. The query will use the default value in that case. If you pass a JSON object that has a value for "orgLogin", that value will override the default value.
Variables can be used in fields and directives to make them accept input values of various literal primitives. An input value can be scalar, like Int, Float, String, Boolean, or Null. It can also be an ENUM value, a list, or an object. The $orgLogin variable represents a scalar string input value for the login argument within the organization field. Read the various GraphQL operation examples we have seen so far and try to identify more input values. For example, try to find where we used an object as an input value.
Now that we know how to define and use variable and values, let’s use them with directives.
3.2. The @include directive
The @include directive can be used after fields (or fragments) to provide a condition (using its if argument). That condition controls whether the field (or fragment) should be included in the response. The use of the @include directive looks like this:
fieldName @include(if: $someTest)
This means to include the field when the query is executed with $someTest set to true and do not include the field when $someTest is set to false. Let’s look at an example from the GitHub API.
Building on the previous OrgInfo query example, let’s assume that you want to conditionally include an organization’s websiteUrl based on whether you are showing full or partial details in the UI. Let’s design a Boolean variable to represent this flag and call it $fullDetails.
This new $fullDetails variable will be required because we are about to use it with a directive. The first line of the OrgInfo query needs to be changed to add the type of $fullDetails:
query OrgInfo($orgLogin: String!, $fullDetails: Boolean!) {
What we want to accomplish now is to only include the websiteUrl when we execute the OrgInfo query with $fullDetails set to true. A simple use of the @include directive can do that. The if argument value in this case will be the $fullDetails variable itself. Here is the full query:
query OrgInfo($orgLogin: String!, $fullDetails: Boolean!) {
organization(login: $orgLogin) {
name
description
websiteUrl @include(if: $fullDetails)
}
}
Go ahead and test this query by executing it with $fullDetails set to true and false and see how the response will now honor that Boolean value and use it to include or exclude the websiteUrl from the response object.
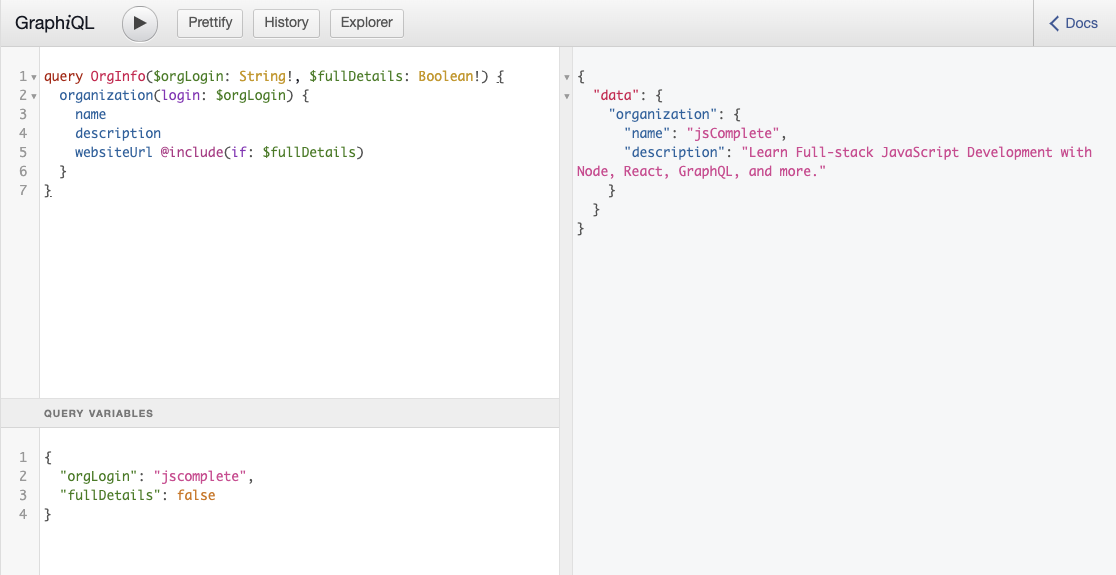
3.3. The @skip directive
This directive is simply the inverse of the @include directive. Just like the @include directive, it can be used after fields (or fragments) to provide a condition (using its if argument). The condition controls whether the field (or fragment) should be excluded in the response. The use of the @skip directive looks like this:
fieldName @skip(if: $someTest)
This means to exclude the field when the query is executed with $someTest set to true and include the field when $someTest is set to false. This is useful to avoid manually negating a variable value, especially if that variable has a negative name already.
Suppose that instead of designing the Boolean variable to be $fullDetails we decided to name it $partialDetails. Instead of manually inverting that variable value in the JSON values object, we can use the @skip directive to use the $partialDetails value directly. The OrgInfo query becomes:
query OrgInfo($orgLogin: String!, $partialDetails: Boolean!) {
organization(login: $orgLogin) {
name
description
websiteUrl @skip(if: $partialDetails)
}
}
Note that a field (or fragment) can be followed by multiple directives. You can repeat @include multiple times or even use both @include and @skip together. All directive conditions must be met for the field (or fragment) to be included or excluded.
Neither @include nor @skip has precedence over the other. When used together, a field will be included only when both the include condition is true and the skip condition is false, and it will be excluded when either the include condition is false or the skip condition is true. The following query will never include websiteUrl no matter what value you use for $partialDetails:
query OrgInfo($orgLogin: String!, $partialDetails: Boolean!) {
organization(login: $orgLogin) {
name
description
websiteUrl @skip(if: $partialDetails) @include(if: false)
}
}
3.4. The @deprecated directive
This is a special directive that can be used in GraphQL servers to indicate deprecated portions of a GraphQL service’s schema, such as deprecated fields on a type or deprecated ENUM values.
When deprecating a field in a GraphQL schema, the @deprecated directive supports a “reason” argument to provide the reason behind the deprecation. The following is the schema language representation of a type that has a deprecated field:
type UserType {
emailAddress: String
email: String @deprecated(reason: "Use 'emailAddress'.")
}
The @deprecated directive can only be used on the server side.
|