GraphQL Problems
Perfect solutions are fairy tales. With the flexibility GraphQL introduces, a door opens to some clear problems and concerns.
1. Security
One important threat that GraphQL makes easier is resource exhaustion attacks (AKA Denial of Service attacks). A GraphQL server can be attacked with overly complex queries that will consume all the resources of the server. It is very simple to query for deep nested relationships (user → friends → friends → friends …) or use field aliases to ask for the same field many times. Resource exhaustion attacks are not specific to GraphQL, but when working with GraphQL you have to be extra careful about them.
There are some mitigations you can do here. You can implement cost analysis on the query in advance and enforce some kind of limits on the amount of data one can consume. You can also implement a time-out to kill requests that take too long to resolve. Also, since a GraphQL service is just one layer in any application stack, you can handle the rate limits enforcement at a lower level under GraphQL.
If the GraphQL API endpoint you are trying to protect is not public and is designed for internal use by your own client applications (web or mobile), you can use a whitelist approach and pre-approve queries that the server can execute. Clients can just ask the servers to execute pre-approved queries using a query unique identifier. While this approach introduces back some dependencies between the servers and the clients, there are some automation strategies that can be used here to mitigate against that. For example, you can give the frontend engineers the freedom to modify the queries and mutations they need to use in development, and then automatically replace them with their unique ids during deployment to production servers. Some client-side GraphQL frameworks are already testing similar concepts.
Authentication and authorization are other concerns that you need to think about when working with GraphQL. Do you handle them before, after, or during a GraphQL resolve process?
To answer this question, think of GraphQL as a DSL (Domain Specific Language) on top of your own backend data-fetching logic. It is just one layer that you could put between the clients and your actual data services. Think of authentication and authorization as another layer. GraphQL will not help with the actual implementation of the authentication or authorization logic. It is not meant for that. But if you want to put these layers behind GraphQL, you can use GraphQL to communicate the access tokens between the clients and the enforcing logic. This is very similar to the way authentication and authorization are usually implemented in REST APIs.
2. Caching
One task that GraphQL makes a bit more challenging is client’s caching of data. Responses from REST APIs are a lot easier to cache because of their dictionary nature. A certain URL gives a certain data so you can use the URL itself as the cache key.
With GraphQL, you can adopt a similar basic approach and use the query text as a key to cache its response. But this approach is limited, not very efficient, and can cause problems with data consistency. The results of multiple GraphQL queries can easily overlap and this basic caching approach would not account for the overlap.
There is a brilliant solution to this problem. A Graph Query means a Graph Cache. If you normalize a GraphQL query response into a flat collection of records and give each record a global unique ID, you can cache those records instead of caching the full responses.
This is not a simple process though. There will be records referencing other records and you will be managing a cyclic graph there. Populating and reading the cache will need query traversal. You will probably need to implement a separate layer to handle this cache logic. However, this method will be a lot more efficient than response-based caching.
3. Server Optimization
Possibly the most important problem that you should be concerned about when working with GraphQL is the problem that is commonly referred to as N+1 SQL queries. GraphQL query fields are designed to be stand-alone functions and resolving those fields with data from a database might result in a new database request per resolved field.
For a simple REST API endpoint logic, it is easy to analyze, detect, and solve N+1 issues by enhancing the constructed SQL queries. For GraphQL dynamically resolved fields, it is not that simple. Luckily Facebook is pioneering one possible solution to this problem: DataLoader.
As the name implies, DataLoader is a utility you can use to read data from databases and make it available to GraphQL resolver functions. You can use DataLoader instead of reading the data directly from databases with SQL queries and DataLoader will act as your agent to reduce the SQL queries you send to the database.
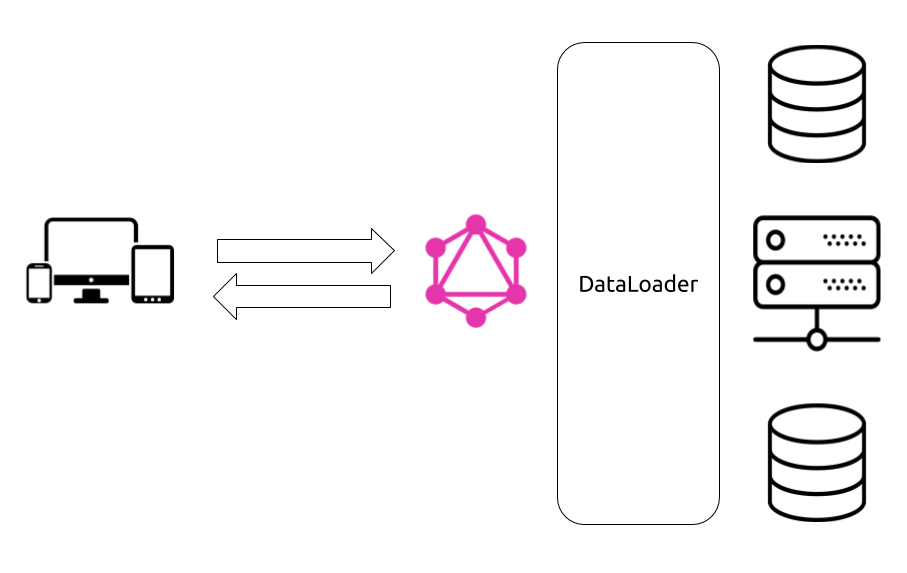
DataLoader uses a combination of batching and caching to accomplish that. If the same client request resulted in a need to ask the database about multiple things, DataLoader can be used to consolidate these questions and batch-load their answers from the database. DataLoader will also cache the answers and make them available for subsequent questions about the same resources.
| There are other SQL optimization strategies that you can use. For example, you can construct the optimal join-based SQL queries by analyzing GraphQL requests. If you are using a relational database with native efficient capabilities to join tables of data and re-use previously parsed queries, then a join-based strategy might actually be more efficient than ids-based batching in many cases but the ids-based batching is probably a lot easier to implement. |