What is GraphQL
GraphQL is a language and a runtime that are designed for the purpose of implementing and consuming data APIs for web and mobile applications and any other client applications. For the clients, GraphQL is a language they can use to declaratively request their exact data needs. For the servers, GraphQL is a runtime for fulfilling these exact clients' data needs with predictable results.
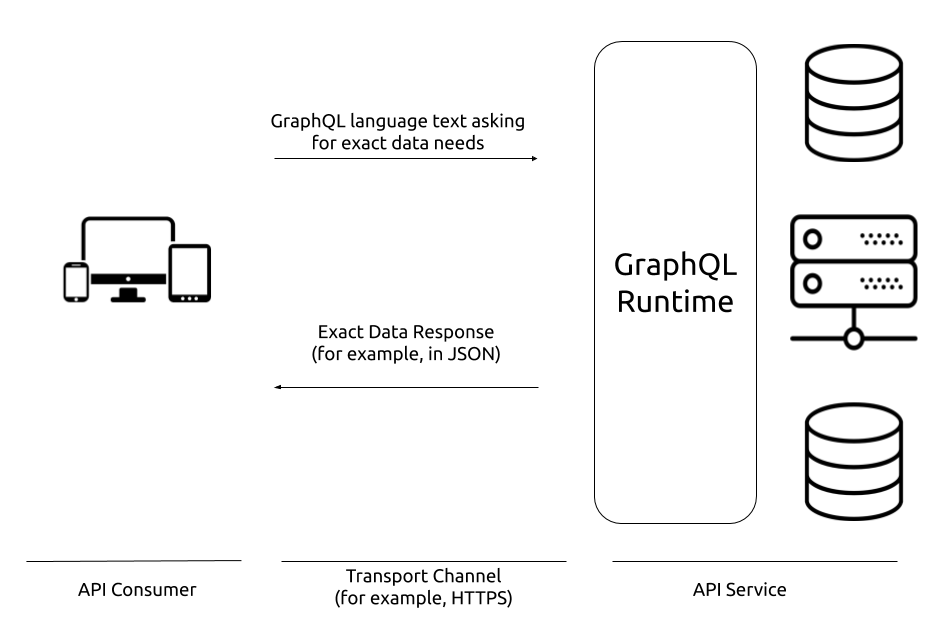
GraphQL provides a structure for servers to describe the data exposed in their APIs. With this structure and the query language it makes available to its clients, GraphQL makes the task of evolving APIs a lot easier. It also enables powerful developer tools among other advantages that we will discuss in the next section.
Although the first talk about GraphQL was at a React.js conference, GraphQL is not specific to React. It can be used in any frontend framework or library and on any platform. You can use GraphQL in frontend applications with a client like Apollo or Relay or by manually making calls to a GraphQL server. You do not need React, Apollo, or Relay to use GraphQL in your applications but these libraries add more value to how you can leverage GraphQL APIs without having to do complex data management tasks.
1. Who is using GraphQL
Facebook designed GraphQL to solve the problems they were facing in their mobile application and to better serve resource-constrained devices over slow networks. Today, GraphQL powers most applications at Facebook, including the main web application at facebook.com, the Facebook mobile application, and Instagram.
Developers interest in GraphQL is very clear and GraphQL’s adoption is growing fast. Besides Facebook, GraphQL is now used in many other major web and mobile applications like GitHub, Yelp, Pinterest, Twitter, The New York Times, Coursera, and Shopify. Given that GraphQL is a young technology, this is an impressive list.
Many other smaller companies are using GraphQL as well. You can see the big list of companies using GraphQL at graphql.org/users.
There are a few conferences dedicated to GraphQL, including GraphQL Summit and GraphQL Conf. They have been attracting new developers who are interested in learning about GraphQL.
Everywhere I go, I see people interested in learning about GraphQL. Everything I write about GraphQL gets immense attention and starts interesting discussions. I predict that GraphQL will see a lot more growth in the next few years. I am betting big on GraphQL because not only it solves many technical challenges about data APIs, but it also solves their more challenging "political" problems! I’ll talk more about that in the "Why GraphQL" section.
|
The word "graph" in GraphQL comes from the fact that the best way to represent data in the real world is through a graph data structure. If you analyze any data model, big or small, you’ll always find it to be a graph that has many top-level nodes and many edges between these nodes. Some models will have a single top-level node making it a tree but a tree is just a special form of a graph. Think about the data model for GitHub.com, for example. The 2 main entities there are "user" and "repository". A simplified version of the GitHub.com graph would have these 2 top-level/entry-point vertices. You either start from a repository object or a user object. From there, you have many edges to go through. In one repository, you can get all the users who forked it. From one user, you can get all the repositories he or she has starred, and so on. You can go from user to repository to user to repository and have an infinite path that way. It’s just a graph. GraphQL embraces this fact by representing the data in terms of vertices (fields) and edges (relations). |
2. The Big Picture
An API, in general, is an interface that enables the communication between multiple components in an application. For example, an API can enable the communication that needs to happen between a web client and a database server. The client needs to tell the server what data it needs and the server needs to fulfill this client’s requirement with objects representing the data they asked for.
There are different types of APIs and every big application needs them. When talking about GraphQL, we are specifically talking about the API type that is used to read and modify data, which is usually referred to as a "Data API".
GraphQL is one option out of many that can be used to provide applications with programmable interfaces to read and modify the data they need from data services. Other options include REST, SOAP, XML, and even SQL itself.
SQL (the Structured Query Language) might be directly compared to GraphQL because "QL" is in both names, after all. Both SQL and GraphQL provide a language to query data schemas. They can both be used to read and modify data.
For example, assuming that we have a table of data about a company’s employees, the following can be an example SQL statement to read data about employees in one department:
SELECT id, first_name, last_name, email, birth_date, hire_date FROM employees WHERE department = 'ENGINEERING'
Here is another example SQL statement that can be used to insert data for a new employee:
INSERT INTO employees (first_name, last_name, email, birth_date, hire_date)
VALUES ('John', 'Doe', '[email protected]', '01/01/1990', '01/01/2020')
You can use SQL to communicate data operations like we did in listing 2.1 and listing 2.2. The relational databases that these SQL statements are sent to usually support different formats for their responses. Each SQL operation type will have a different response. A SELECT operation might return a single row or multiple rows. An INSERT operation might return just a confirmation, the inserted rows, or an error response.
| While possible, SQL would not be a good language to use for communicating data requirements directly by mobile and web applications. SQL is simply too powerful and too flexible. Exposing your exact database structure publicly would be a very challenging security problem. You can put SQL behind another service layer but that means you need to come up with a parser and analyzer to perform operations on users' SQL queries before sending them to the database and that is simply not an easy thing to do. Besides, SQL would also introduce more challenges for caching data and loading it from multiple databases. |
While SQL is directly supported by most relational databases, GraphQL is its own thing. GraphQL needs a runtime service of its own. You cannot just start querying databases using the GraphQL query language (at least not yet). You will need to use a service layer that supports GraphQL or implement one yourself.
JSON is a language that can be used to communicate data. Here is a JSON text that can represent John’s data:
{
"data": {
"employee":{
id: 42,
name: "John Doe",
email: [email protected],
birthDate: "01/01/1990",
hireDate: "01/01/2020"
}
}
}
| Note how the data communicated about John does not have to be in the exact "structure" of how it is saved in the database. In JSON, I used camel-case property names, and I combined first_name and last_name into one name field. |
JSON is a popular language to communicate data from API servers to client applications. Most of the modern data API servers use JSON to fulfill the data requirements of a client application. GraphQL servers are no exception; JSON is the popular choice to fulfill the requirements of GraphQL data requests.
JSON can also be used by client applications to communicate their data requirements to API servers. For example, here is a possible JSON object that can be used to communicate the data requirement for the employee object response in Listing 2.3:
{
"select": {
"fields": ["name", "email", "birthDate", "hireDate"],
"from": "employees",
"where": {
"id": {
"equals": 42
}
}
}
}
GraphQL for client applications is another language they can use to express their data requirements. The following is how the same previous data requirement can be expressed with a GraphQL query:
{
employee(id: 42) {
name
email
birthDate
hireDate
}
}
The GraphQL query in listing 2.5 represents the same data need as the JSON object in listing 2.4, but as you can see it has a different and shorter syntax. A GraphQL server can be made to understand this syntax and translate it into what the actual data storage engine can understand (for example, it would translate it into SQL statements for a relational database). Then, the GraphQL server can take what the storage engine responds with and translate it into something like JSON or XML and send it back to the client application.

This is nice because no matter what storage engine (or multiple storage engines) you have to deal with, with GraphQL you make API servers and client applications both work with a universal language for requests and a universal language for responses.
In a nutshell, GraphQL is all about optimizing data communication between a client and a server. This includes the client asking for the needed data, communicating that need to the server, the server preparing a fulfillment for that need, and communicating that fulfillment back to the client. GraphQL allows clients to ask for the exact data they need and make it easier for servers to aggregate data from multiple data storage resources.
At the core of GraphQL, there is a strong type system that is used to describe the data and organize the APIs. This type system gives GraphQL many advantages on both the server and the client sides. Types ensure that the clients ask for only what is possible and provide clear and helpful errors. Clients can use types to minimize any manual parsing of data elements. GraphQL type system allows for rich features like having an introspective API and being able to build powerful tools for both clients and servers. One of the popular GraphQL tools that relies on this concept is called GraphiQL, which is a feature-rich browser-based editor to explore and test GraphQL requests.
3. GraphQL is a specification
Although Facebook engineers started working on GraphQL in 2012, it was 2015 when they released a public specifications document for it. This document is currently hosted at graphql.github.io/graphql-spec and it is maintained by a community of companies and individuals on GitHub. GraphQL is still an evolving language, but the specifications document was a genius start for the project because it defined standard rules and practices that all implementers of GraphQL runtimes need to adhere to. There have been many implementations of GraphQL libraries in many different programming languages and all of them closely follow the specification document and update their implementations when that document is updated. If you work on a GraphQL project in Ruby and later switch to another project in Scala, the syntax will change but the rules and practices will remain the same.
Alongside the specification document, Facebook also released a reference implementation library for GraphQL runtimes in JavaScript. JavaScript is the most popular programming language and the one closest to mobile and web applications which are two of the popular channels where using GraphQL can make a big difference. The reference JavaScript implementation of GraphQL is hosted at github.com/graphql/graphql-js. I’ll refer to this implementation as "GraphQL.js".
I started learning GraphQL by reading the documentation and the specification document. The specification document is a bit technical, but you can still learn a lot from it by reading its important parts. This book will not cover each and everything in the specification document, so I recommend that you skim through it once you are done with the book.
The specification document starts by describing the syntax of the GraphQL language. Let’s talk about that first.
4. GraphQL is a language
While the Q (for query) is right there in the name, querying is associated with reading. However, GraphQL can be used for both reading and modifying data. When you need to read data with GraphQL you use queries and when you need to modify data you use mutations. Both queries and mutations are part of the GraphQL language.
| Besides queries and mutations, Graphql also supports a third request type which is called a subscription and it’s used for real-time data monitoring requests. |
This is just like how you use SELECT statements to read data with SQL and you use INSERT, UPDATE, and DELETE statements to modify it. The SQL language has certain rules that you must follow. For example, a SELECT statement requires a FROM clause and can optionally have a WHERE clause. Similarly, the GraphQL language has certain rules that you must follow as well. For example, a GraphQL query must have a name or be the only query in a request. You will learn about the rules of the GraphQL language in the next few chapters.
Unlike SQL, which is a language for databases, GraphQL is a language for APIs. GraphQL is not a database technology and it is completely database-agnostic.
Both the GraphQL and the SQL languages are smaller in scope and different from programming languages like JavaScript or Python. You cannot use the GraphQL language to create User Interfaces or perform complex computations. These query languages have more specific use cases and they often require the use of other programming languages to make them work.
Never the less, I would like you to first think of these query languages by comparing them to programming languages and even to the languages that we speak, like English. This is a very limited-scope comparison, but I think in the case of GraphQL it will make you understand and appreciate a few things about it.
The evolution of programming languages in general is making them closer and closer to the human languages that we speak. Computers used to only understand imperative instructions and that is why we have been using imperative paradigms to program them. However, computers today are starting to understand declarative paradigms and you can program them to understand wishes. Declarative programming has many advantages (and disadvantages), but what makes it such a good idea is that we always prefer to reason about problems in declarative ways. Declarative thinking is easy for us.
We can use the English language to declaratively communicate data needs and fulfillments. For example, imagine that John is the client and Jane is the server. Here is an English data communication session:
John can also easily ask both questions in one sentence and Jane can easily answer them both by adding more words to her answer.
When we communicate using the English language, we understand special expressions like "a bit over" and "a bit under". Jane also understood that the incomplete second question is related to the first one. Computers, on the other hand, are not very good (yet) at understanding things from the context. They need more structure.
GraphQL is just another declarative language that John and Jane can use to do that data communication session. It is not as good as the English language, but it is a structured language that computers can easily parse and use. For example, here’s a hypothetical single GraphQL query that can represent both of John’s questions to Jane:
{
timeLightNeedsToTravel(toPlanet: "Earth") {
fromTheSun: from(star: "Sun")
fromTheMoon: from(moon: "Moon")
}
}
The example GraphQL request in listing 2.6 uses a few of the GraphQL language parts like fields (timeLightNeedsToTravel and from), parameters (toPlanet, star, and moon), and aliases (fromTheSun and fromTheMoon). These are like the verbs and nouns of the English language. You will learn about all the syntax parts that you can use in GraphQL requests in the next few chapters.
5. GraphQL is a service
If you teach a client application to speak the GraphQL language, it will be able to declaratively communicate any data requirements to a backend data service that also speaks GraphQL. To teach a data service to speak GraphQL, you need to implement a runtime layer and expose that layer to the clients who want to communicate with the service. Think of this layer on the server side as simply a translator of the GraphQL language, or a GraphQL-speaking agent who represents the data service. GraphQL is not a storage engine, so it cannot be a solution on its own. This is why you cannot have a server that speaks just GraphQL and you need to implement a translating runtime layer.
A GraphQL service can be written in any programming language and it can be conceptually split into two major parts: structure and behavior.
-
The structure is defined with a strongly-typed schema. A GraphQL schema is like a catalog of all the operations a GraphQL API can handle. It simply represents the capabilities of an API. GraphQL client applications use the schema to know what they can ask for. The typed nature of the schema is a core concept in GraphQL. The schema is basically a graph of fields which have types and this graph represents all the possible data objects that can be read (or updated) through the service.
-
The behavior is naturally implemented with functions that in the GraphQL world are named resolver functions and they represent most of the smart logic behind GraphQL’s power and flexibility. Each field in a GraphQL schema is backed by a resolver function. A resolver function defines what data to fetch for its field.
A resolver function is where we give instructions for the runtime service about how and where to access the raw data. For example, a resolver function might issue a SQL statement to a relational database, read a file’s data directly from the operating system, or update some cached data in a document database. A resolver function is directly related to a field in a GraphQL request and it can represent a single primitive value, an object, or a list of values or objects.
| Resolver functions are why GraphQL is often compared to the remote procedure call (RPC) distributed computing concept. GraphQL is essentially a way for clients to invoke remote - resolver - functions. |
5.1. A schema and resolvers example
To understand how resolvers work, let’s take the query in Listing 2.5 (simplified) and assume a client sent it to a service:
query {
employee(id: 42) {
name
email
}
}
The service can receive and parse any request. It’ll then try to validate the request against its schema. The schema has to support a top-level employee field and that field has to represent an object that has an id argument, a name field, and an email field. Fields and arguments need to have types in GraphQL. The id argument can be an integer. The name and email fields can be strings. The employee field is a custom type (representing that exact id/name/email structure).
Just like the client-side query language, the GraphQL community standardized a server-side language dedicated to creating GraphQL schema objects. This language is known as the "Schema Language" (AKA "SDL", Schema Definition Language). Here’s an example to represent the "Employee" type using the schema language:
type Employee(id: Int!) {
name: String!
email: String!
}
This is the custom Employee type that represents the structure of an employee "model". An object of the employee model can be looked up with an integer id and it has name and email string fields.
| The exclamation marks after the types mean that they cannot be empty. A client cannot ask for an employee field without specifying an id argument, and a valid server response to this field must include a name string and an email string. |
| The schema language type definitions are like the CREATE statements that we use to define tables (and other database schema elements). |
Using this type, the GraphQL service can conclude that the GraphQL query in Listing 2.7 is valid because it matches the supported type structure. The next step is to prepare the data it is asking for. To do that, the GraphQL service traverses the tree of fields in that request and invokes the resolver function associated with each field in it. It’ll then gather the data returned by these resolver functions and use it to form a single response.
This example GraphQL service needs to have at least 3 resolver functions: one for the employee field, one for the name field, and one for the email field.
The employee field’s resolver function might, for example, do a query like: select * from employees where id = 42. This SQL statements returns all columns available on the employees table. Let’s say the employees table happen to have the following fields: id, first_name, last_name, email, birth_date, hire_date
So the employee field’s resolver function for employee #42 might return an object like:
{
id: 42,
first_name: 'John',
last_name: 'Doe',
email: '[email protected]'
birth_date: "01/01/1990",
hire_date: "01/01/2020"
}
The GraphQL service continues to traverse the fields in the tree one by one invoking the resolver function for each. Each resolver function is passed the result of executing the resolver function of its parent node. So both the name and email resolver function receive the object in Listing 2.9 (as their first argument).
Let’s say we have the following (JavaScript) functions representing the server resolver functions for the name and email fields:
// Resolver functions
const name => (source) => `${source.first_name} ${source.last_name}`;
const email => (source) => source.email;
The source object here is the parent node. For top-level fields, the source object is usually undefined (because there is no parent).
The email resolver function is known as a "trivial" resolver because the "email" field name matches the "email" property name on the parent source object. Some GraphQL implementations (for example, the JavaScript one) have these trivial resolvers built-in and used as default resolvers if no resolvers were found for a field.
|
The GraphQL service will use all the responses of these 3 resolver functions to put together the following single response for the query in Listing 2.7:
{
data: {
employee: {
name: 'John Doe',
email: '[email protected]'
}
}
}
| GraphQL does not require any specific data serialization format but JSON is the most popular one. All the examples in this book will use the JSON format. |