Why GraphQL
GraphQL APIs are often compared to REST APIs because the latter has been the most popular choice for data APIs demanded by web and mobile applications. GraphQL provides a more efficient "technology" alternative to REST, but there are other options out there that can provide the same efficient technology. You can for example use a JSON-based API with a custom query language, or you can implement the Open Data Protocol (OData) on top of a REST API. Experienced backend developers have been creating efficient technologies for data APIs long before GraphQL.
The most important reason why I think GraphQL is a game changer is not about technology at all but rather about communication and documentation. If you ask me to answer the "Why GraphQL" question with just a single word, that word would be: Standards!
GraphQL provides standards and structures to implement API features in maintainable and scalable ways while the other alternatives lack such standards.
GraphQL makes it mandatory for data API servers to publish documentation about their capabilities and offer a way for client applications to know everything that’s available for them on these servers, and know exactly how to use the APIs. This kind of documentation and validation power is known as the GraphQL schema and it has to be part of every GraphQL API. Clients can ask the service about its schema using the GraphQL language. We’ll see examples of that soon.
A GraphQL schema is basically a capabilities document that has a list of all the questions that can be asked by clients of the GraphQL server. This gives frontend developers a lot of power and control to explore, construct, validate, test, and accurately perform their data need communication without depending on backend developers.
Other solutions can be made better by adding similar documentations as well, the unique thing about GraphQL here is that the documentation is mandatory. You cannot create a GraphQL server without the standard schema. You cannot have out-of-date documentation. You cannot forget to document a use-case. You cannot offer different ways to use APIs because you have standards to work with. Most importantly, you do not need to maintain the documentation of your API separately from that API. GraphQL documentation is built-in and it’s first class!
The mandatory GraphQL schema represents the possibilities and the limits of what can be answered by the GraphQL service, but there is some flexibility in how to use the schema because we are talking about a graph of nodes here and graphs can be traversed using many paths. This flexibility is one of the great benefits of GraphQL because it allows backend and frontend developers to make progress in their projects without needing to constantly coordinate that progress with each other. It basically decouples clients from servers and allows both of them to evolve and scale independently. This enables much faster iteration in both frontend and backend products.
I think this standard schema is among the top benefits of GraphQL but let’s also talk about the technological benefits of GraphQL as well.
One of the biggest technological reasons to consider a GraphQL layer between clients and servers, and perhaps the most popular one, is efficiency. API clients often need to ask the server about multiple resources and API server usually knows how to answer questions about a single resource. As a result, the client ends having to communicate with the server multiple times to gather all the data it needs.
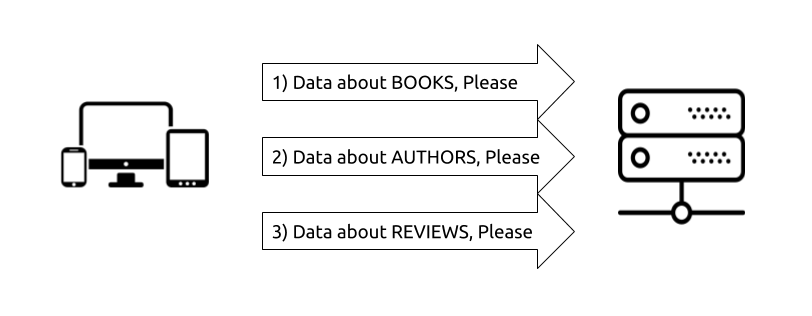
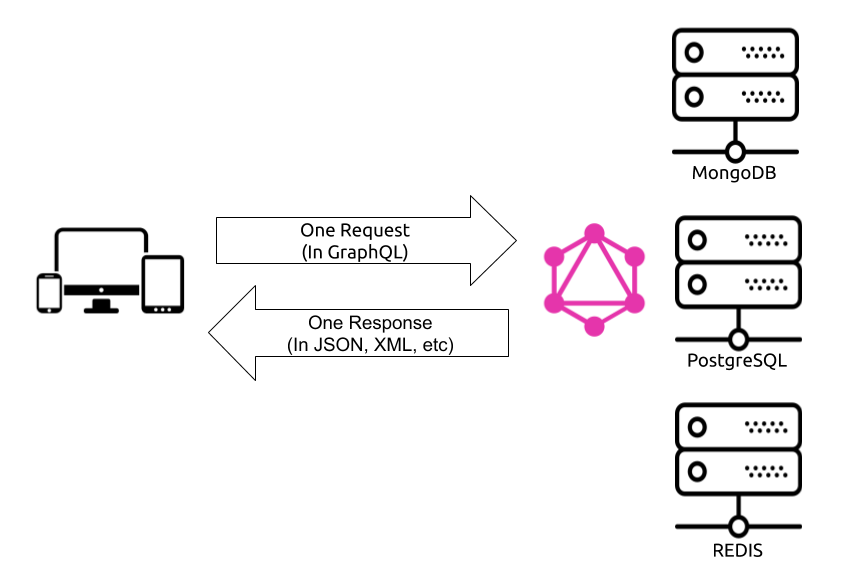
With GraphQL, you can basically shift this multi-request complexity to the backend and have your GraphQL runtime deal with it. The client asks the GraphQL service a single question and gets a single response that has exactly what the client needs. You can customize a REST-based API to provide one exact endpoint per view, but that’s not the norm. You will have to implement it without a standard guide.

Another big technological benefit about GraphQL is communicating with multiple services. When you have multiple clients requesting data from multiple data storage services (like PostgreSQL, MongoDB, and a REDIS cache), a GraphQL layer in the middle can simplify and standardize this communication. Instead of a client going to the multiple data services directly, you can have that client communicate with the GraphQL service. Then, the GraphQL service will do the communication with the different data services. This is how GraphQL isolates the clients from needing to communicate in multiple languages. A GraphQL service translates a single client’s request into multiple requests to multiple services using different languages.
1. What about REST APIs?
GraphQL can be thought of as simply an alternative to REST APIs. But why do we need an alternative? What is wrong with REST APIs?
The biggest "relevant" problem with REST APIs here is the clients need to communicate with multiple data API endpoints. REST APIs are an example of servers that require clients to do multiple network round-trips to get data. A REST API is basically a collection of endpoints where each endpoint represents a resource, so when a client needs data about multiple resources it needs to perform multiple network requests to that REST API and then put together the data it needs by combining the multiple responses it receives. This is a big problem, especially for mobile applications, because mobile devices usually have processing, memory, and network constraints.
Furthermore, in a REST API there is no client request language. Clients do not have control over what data the server will return because they do not have a language to communicate their exact needs. More accurately, the language available for clients of a REST API is very limited. For example, the READ REST API endpoints are either:
-
GET /ResourceName- to get a list of all the records for that resource, or -
GET /ResourceName/ResourceID- to get a single record identified by an ID.
In a pure REST API (not a customized one) a client cannot specify which fields to select for a record in that resource. That information is in the REST API service itself and the REST API service will always return all of the fields regardless of which ones the client actually needs. GraphQL’s term for this problem is over-fetching of information that is not needed. It is a waste of network and memory resources for both the client and the server.
One other big problem with REST APIs is versioning. If you need to support multiple versions that usually means new endpoints. This leads to more problems while using and maintaining these endpoints and it might be the cause of code duplication on the server.
| The REST APIs problems mentioned here are the ones specific to what GraphQL is trying to solve. They are certainly not all of the problems of REST APIs. |
REST APIs eventually turn into a mix that has regular REST endpoints plus custom ad-hoc endpoints crafted for performance reasons. This is where GraphQL offers a much better alternative.
It is important to point out here that REST APIs have some advantages over GraphQL APIs. For example, caching a REST API response is a lot easier than caching a GraphQL API response, as you will see in the next chapter. Also, optimizing the code for a REST endpoint is potentially a lot easier than optimizing the code for a generic single endpoint. There is no one magical solution that fixes all problems without introducing new challenges. REST APIs have their place and when used correctly, both GraphQL and REST have their great applications. There is also nothing that prohibits the use of both of them together in the same system.
2. The GraphQL Way
To see the GraphQL way for solving the problems of REST APIs that we talked about, you need to understand the concepts and design decisions behind GraphQL. Here are the major ones:
2.1. 1) The Typed Graph Schema
To create a GraphQL API, you need a typed schema. A GraphQL schema contains fields that have types. Those types can be primitive or custom. Everything in the GraphQL schema requires a type.
GraphQL speaks to the data as a graph and data is naturally a graph. If you need to represent any data, the right structure is a graph. The GraphQL runtime allows us to represent our data with a graph API that matches the natural graph shape of that data.
2.2. 2) The Declarative Language
GraphQL has a declarative nature for expressing data requirements. It provides clients with a declarative language for them to express their data needs. This declarative nature enables a thinking model in the GraphQL language that is close to the way we think about data requirements in English and it makes working with a GraphQL API a lot easier than the alternatives. This thinking model is another top reason why I personally believe GraphQL is a big deal.
2.3. 3) The Single Endpoint and the Client Language
To solve the multiple round-trip problem, GraphQL makes the responding server work as just one endpoint. Basically, GraphQL takes the custom endpoint idea to an extreme and just makes the whole server a single smart endpoint that can reply to all data requests.
The other big concept that goes with this single smart endpoint concept is the rich client request language that is needed to work with that single endpoint. Without a client request language, a single endpoint is useless. It needs a language to process a custom request and respond with data for that custom request.
Having a client request language means that the clients will be in control. They can ask for exactly what they need and the server will reply with exactly what they are asking for. This solves the problem of over-fetching the data that is not needed.
Furthermore, having clients asking for exactly what they need enables backend developers to have more useful analytics of what data is being used and what parts of the data is in higher demand. This is very useful data. For example, it can be used to scale and optimize the data services based on usage patterns. It can also be used to detect abnormalities and clients' version changes.
2.4. 4) The Simple Versioning
When it comes to versioning, GraphQL has an interesting take. Versioning can be avoided all together. Basically, you can just add new fields and types without removing the old ones because you have a graph and you can flexibly grow the graph by adding more nodes. You can leave paths on the graph for old APIs and introduce new ones. The API just grows and no new endpoints are needed. Clients can continue to use older features, and they can also incrementally update their code to use new features.
By using a single evolving version, GraphQL APIs give clients continuous access to new features and encourage cleaner and more maintainable server code.
This is especially important for mobile clients because you cannot control the version of the API they are using. Once installed, a mobile app might continue to use that same old version of the API for years. On the web, it is easy to control the version of the API because you can just push new code and force all users to use it. For mobile apps, this is a lot harder to do.
This simple versioning approach has some challenges. Keeping old nodes forever introduces some downsides. More maintenance effort will be needed to make sure old nodes still work as they should. Furthermore, users of the APIs might be confused about which fields are old and which are new. GraphQL offers a way to deprecate (and hide) older nodes so that readers of the schema only see the new ones. Once a field is deprecated, the maintainability problem becomes a question of how long old users will continue to use it. The great thing here is that as a maintainer, you can confidently answer the questions "is a field still being used?" and "how often is a field being used?" thanks to the client query language. The removal of not-used deprecated fields can even be automated.
3. REST APIs and GraphQL APIs in action
Let’s go over a one-to-one comparison example between a REST API and a GraphQL API. Imagine that you are building an application to represent the Star Wars films and characters. The first UI you are tackling is a view to show information about a single Star Wars character. This view should display the character’s name, birth year, planet name, and the titles of all the films in which they appeared. For example, for Darth Vader, along with his name, the view should display his birth year (41.9BBY), his planet’s name (Tatooine), and the titles of the 4 Star Wars film in which he appeared (A New Hope, The Empire Strikes Back, Return of the Jedi, Revenge of the Sith).
As simple as this view sounds, you are actually dealing with three different resources here: Person, Planet, and Film. The relationship between these resources is simple. We can easily guess the shape of the data needed here. A person object belongs to one planet object and it will have one or more films objects.
The JSON data for this view could be something like:
{
"data": {
"person": {
"name": "Darth Vader",
"birthYear": "41.9BBY",
"planet": {
"name": "Tatooine"
},
"films": [
{ "title": "A New Hope" },
{ "title": "The Empire Strikes Back" },
{ "title": "Return of the Jedi" },
{ "title": "Revenge of the Sith" }
]
}
}
}
Assuming that a data service can give us this exact structure, here is one possible way to represent its view with a frontend component library like React.js:
// The Container Component: <PersonProfile person={data.person}></PersonProfile> // The PersonProfile Component: Name: {data.person.name} Birth Year: {data.person.birthYear} Planet: {data.person.planet.name} Films: {data.person.films.map(film => film.title)}
This is a very simple example. Our experience with Star Wars helped us here to design the shape of the needed data and figure out how to use it in the UI.
Note one important thing about the UI view in listing 3.2, its relationship with the JSON data object in listing 3.1 is very clear. The UI view used all the "keys" from the JSON data object. See the values within curly brackets in listing 3.2.
Now, how can you ask a REST API service for the data in listing 3.1?
You need a single person’s information. Assuming that you know the ID of that person, a REST API is expected to expose that information with an endpoint like:
GET - /people/{id}
This request will give you the name, birthYear, and other information about the person. A REST API will also give you access to the ID of this person’s planet and an array of IDs for all the films this person appeared in.
The JSON response for this request could be something like:
{
"name": "Darth Vader",
"birthYear": "41.9BBY",
"planetId": 1
"filmIds": [1, 2, 3, 6],
... [other information that is not needed for this view]
}
Then to read the planet’s name, you ask:
GET - /planets/1
And to read the films titles, you ask:
GET - /films/1 GET - /films/2 GET - /films/3 GET - /films/6
Once you have all six responses from the server, you can combine them to satisfy the data needed by the view.
Besides the fact that you had to do 6 network round-trips to satisfy a simple data need for a simple UI, the whole approach here is imperative. You gave instructions for how to fetch the data and how to process it to make it ready for the view. For example, you have to deal with the planet’s and the films' IDs although the view did not really need them. You had to manually combine multiple data objects although you are implementing a single view that naturally need just a single data object.
Try asking for this data from a REST API yourself. The Star Wars data has an excellent REST API which is hosted at https://swapi.co/. Go ahead and try to construct the same previous data object there. The names of the data elements might be a bit different, but the endpoints structure is the same. You will need to do exactly 6 API calls. Furthermore, you will have to over-fetch information that the view does not need.
Of course, SWAPI is just one pure implementation of a REST API for this data. There could be better custom implementations that will make this view’s data needs easier to fulfill. For example, if the API server implemented nested resources and understood the relationship between a person and a film, you could read the films data (along with the person data) with something like:
GET - /people/{id}/films
However, a pure REST API would not have that out-of-the-box. You would need to ask the backend engineers to create this custom endpoint for your view. This is the reality of scaling a REST API. You just add custom endpoints to efficiently satisfy the growing clients' needs. Managing custom endpoints like these is hard.
For example, if you customized your REST API endpoint to return the films data for a character, that would work great for this view that you are currently implementing. However, in the future, you might need to implement a shorter or longer version of the character’s profile information. Maybe you will need to show only one of their films or show the description of each film in addition to the title. Every new requirement will mean a change is needed to customize the endpoint furthermore or even come up with brand new endpoints to optimize the communication needed for the new views. This approach is simply limited.
Let’s now look at the GraphQL approach.
A GraphQL server will be just a single smart endpoint. The transport channel would not matter. If you are doing this over HTTP, the HTTP method certainly would not matter either. Let’s assume that you have a single GraphQL endpoint exposed over HTTP at /graphql.
Since you want to ask for the data you need in a single network round-trip, you will need a way to express the complete data needs for the server to parse. You do this with a GraphQL query:
GET or POST - /graphql?query={...}
A GraphQL query is just a string, but it will have to include all the pieces of the data that you need. This is where the declarative power comes in.
Let’s compare how this simple view’s data requirement can be expressed with English and with GraphQL.
| In English | In GraphQL |
|---|---|
The view needs: a person’s name, birth year, planet’s name, and the titles of all their films. |
{
person(ID: ...) {
name
birthYear
planet {
name
}
films {
title
}
}
}
|
Can you see how close the GraphQL expression is to the English one? It is as close as it can get. Furthermore, compare the GraphQL query with the original JSON data object that we started with.
| GraphQL Query (Question) | Needed JSON (Answer) |
|---|---|
{
person(ID: ...) {
name
birthYear
planet {
name
}
films {
title
}
}
}
|
{
"data": {
"person": {
"name": "Darth Vader",
"birthYear": "41.9BBY",
"planet": {
"name": "Tatooine"
},
"films": [
{ "title": "A New Hope" },
{ "title": "The Empire Strikes Back" },
{ "title": "Return of the Jedi" },
{ "title": "Revenge of the Sith" }
]
}
}
}
|
The GraphQL query is the exact structure of the JSON data object, except without all the "value" parts (bolded in table 1.2). If you think of this in terms of a question-answer relation, the question is the answer statement without the answer part.
The same relationship applies to a GraphQL query. Take a JSON data object, remove all the "answer" parts (which are the values), and you end up with a GraphQL query suitable to represent a question about that JSON data object.
Now, compare the GraphQL query with the UI view that used it. Every element of the GraphQL query is used in the UI view and every dynamic part that is used in the UI view appears in the GraphQL query.
This obvious mapping is one of the greatest powers of GraphQL. The UI view knows the exact data it needs and extracting that requirement from the view code is fairly easy. Coming up with a GraphQL query is simply the task of extracting what is used as variables directly from the UI views. If you think about this in terms of multiple nested UI components, every UI component can ask for the exact part of the data that it needs and the application data needs can be constructed by putting these partial data needs together. GraphQL provides a way for a UI component to define the partial data need via a feature called "Fragments". You will learn about GraphQL fragments in the last chapter of this book.
Furthermore, if you invert this mapping model, you will find another powerful concept. If you have a GraphQL query, you know exactly how to use its response in the UI because the query will be the same "structure" as the response. You do not need to inspect the response to know how to use it and you do not need any documentation about the API. It is all built-in.
Star Wars data has a GraphQL API hosted at graphql.org/swapi-graphql. You can use the GraphiQL editor available there to test a GraphQL query. We’ll talk about the GraphiQL editor soon but you can go ahead and try to construct the example data person object there. There are a few minor differences that you will learn about later in the book, but here is the official query you can use against this API to read the data requirement for the same view (with Darth Vader as an example):
{
person(personID: 4) {
name
birthYear
homeworld {
name
}
filmConnection {
films {
title
}
}
}
}
Just paste this query in the editor area and hit the run button. This request will give you a response structure very close to what the view used, you expressed this data need in a way that is close to how you would express it in English, and you will be getting all of this data in a single network round-trip.
GraphQL offers many advantages over REST APIs but let’s also talk about the challenges GraphQL brings to the table as well.